
Onchain Intelligence Value Chain
Deep Context is the last bottleneck for hedge-fund-grade AI.
TL;DR:
- Deep Context Data is the key to turning AI into a hedge-fund-grade capital allocator.
- AI isn't the bottleneck at the decision layer. Deep context is.
- Deep Context data availability unlocks a massive AI productivity gap → from analysis to capital allocation decisions.
Deep Context Problem introduction
AI models and abundance of onchain data in free and paid APIs/MCPs allows one to easily build vibecoded dashboards and perform capital allocations analysis.
However, the simple data is cheap. But context & verification isn't.
Data itself isn't valuable if it lacks context, verification, and correct understanding of what it actually represents.
Larry Elission $ORCL highlighted that only private and verified data provides a competitive edge for AI applications.
This problem is also relevant for Web3:
- High-quality analysis requires not only common metrics but also complex, protocol-specific ones.
- Results quality depends on external APIs and pre-packaged datasets.
- The missing piece is not access to data, but deep context, attribution, and verification.
For example, complex outcomes such as token holders revenue still require human interventions and cannot be entirely streamlined by AI:
"Claude still make many mistakes that I debugging took 10x time than writing this article so take the spreadsheet with a grain of salt (link at the end of the post)." Ignas Defi
Below we explore the Onchain Intelligence Value Chain: how data is processed from raw onchain data to portfolio-grade signals.
Onchain Intelligence Value Chain
The Value Chain starts from raw data extraction and completes with decision-making:
raw (indexing) → low context → deep context → decision/action
There are four logical steps necessary to convert raw onchain data into decisions:
- Level 0: Raw data (Indexed Data)
- Level 1: Simple Metrics (Aggregation & Labeling)
- Level 2: Deep Context Data (Attribution Model, Risks, Products/Protocol Economics)
- Level 3: Decision-making (Strategies & Allocation)
Below we provide more details on each step, typical results, and execution complexity:
Table 1. The levels of data processing in Onchain Intelligence Value Chain.
| Level | Output | Stack Layer | Why it matters | Scalability with AI |
|---|---|---|---|---|
| 0 | Raw indexed data: not decision-ready | Data indexing layer | It is the foundation, every higher layer depends on it. | Moderate: infra-heavy but can be done with AI if use reliable RPC provider |
| 1 | Structured datasets with basic semantics: - asset transaction volume - capital flows - spot prices - number of market events (swaps, liquidations) - token supply metrics (whales, holders, buying/selling) - Yield metrics for standardized Defi products | Simple Attribution Layer | Essential data for research | Scalable: repetitive and easy to validate |
| 2 | Decision-ready metrics and signals Protocols financials (revenue/expenses) Tokens financials (revenue, valuation, multipliers) Complex Defi protocols metrics & usage results (such as P&L) Risks metrics | Deep Context Attribution layer | Protocol-specific context, turning data into meaning and then → decisions | Not AI-scalable (yet): it requires a continuously maintained attribution model / knowledge graph per protocol, plus rigorous verification. Sometimes also requires knowledge & data for external protocols |
| 3 | Decisions & forecasts: Results of hypothesis testing Investment strategy & capital allocation Automated portfolio management for custom purposes Ready-to-execute signals | Interpretation layer, leading to capital allocation actions. | The end product for investors | Can scale only with LvL 2 data, because AI is good at synthesis, ranking, scenario comparison, and policy-driven decisioning. |
LvL 2 Deep context metrics aren't about computing a formula, they're about maintaining an Attribution Model or Knowledge Graph for each protocol (system design, contracts, dependencies, parameters, roles, risks, and economic attribution):
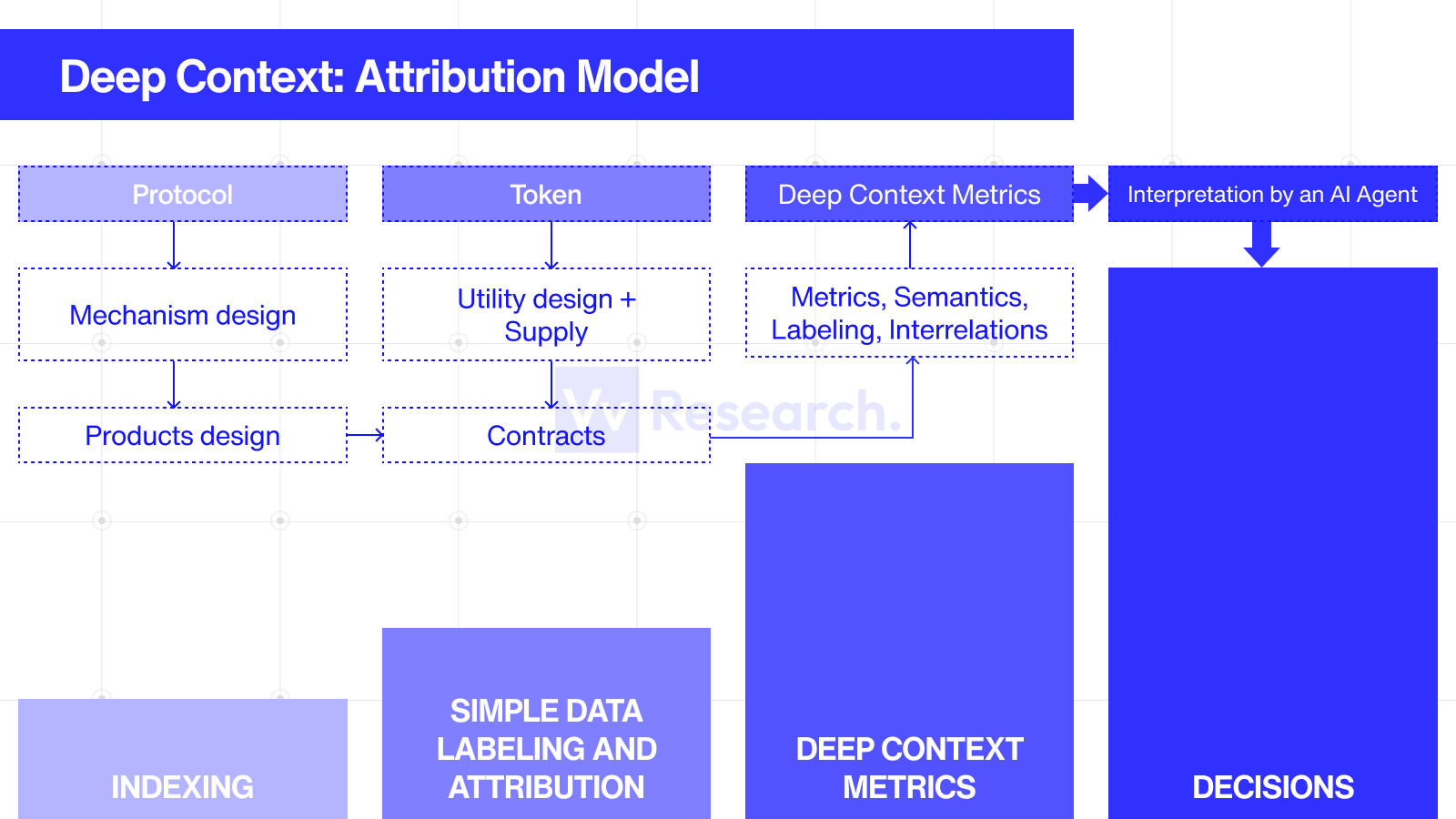
AI can speed up the discovery phase and first assess conclusions, but without verifiable context and an audit trail, the human-in-the-loop bottleneck remains.
Value of data, complexity, and production costs
Below is a qualitative chart illustrating the value of datasets delivered at each level versus the complexity required to produce and maintain them:
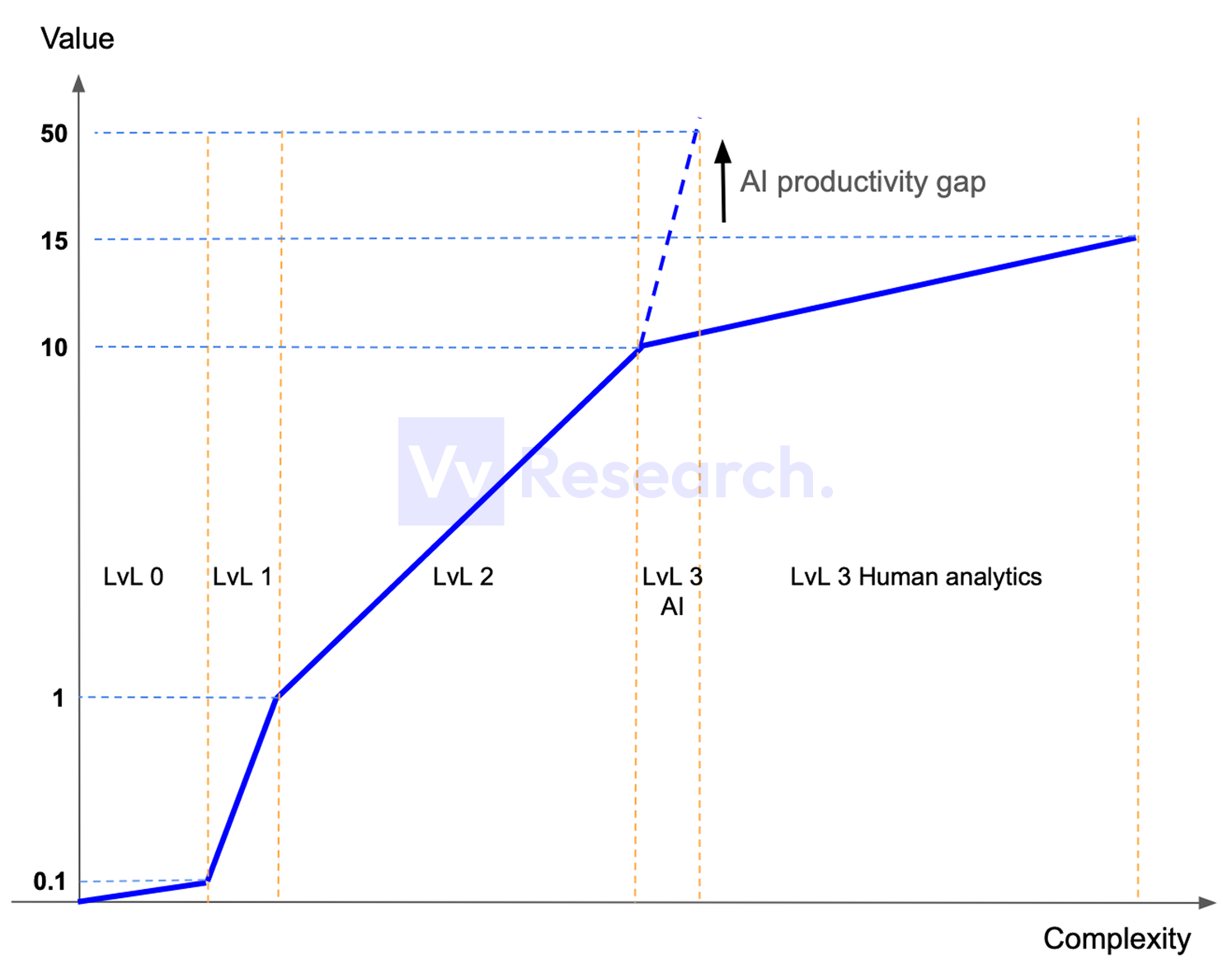
The Value = 1 is the minimal value that is needed to produce decisions based on the available data. Below 1 data is not ready to be used for decision-making.
How to read this chart:
- The x-axis is Complexity (how complex/expensive it is to produce and maintain the data).
- The y-axis is Value (how useful/monetizable the output is for decision-making).
- The solid blue line shows how value increases as you move up the stack with more context.
- The dashed blue line illustrates the potential jump in output once AI is fed decision-grade context (the "AI productivity gap").
What happens on each level:
- LvL 0: Data indexing (raw data). Doesn't produce insights but is essential for building any datasets
- LvL 1: Simple data labeling & attribution. Scales with AI due to repetitive attribution patterns & easy validation.
- LvL 2: Deep Context Data that is ready to be used for decision-making and is a foundation for actionable insights. The value growth is 10x vs. LvL 1, but it still cannot be scaled with AI (Attribution Models required)
- LvL 3: Interpretation Layer: what to do to make money. It comes down to decision-making and capital allocation actions. Can scale with AI, but requires LvL 2 data & context.
The pricing for data correlates with production complexity:
- LvL 0 & 1 data is relatively abundant (ready-to-use infrastructure)
- LvL 2 quality data is rare, priced much higher, sometimes not available at all (ready-to-use results based on deep context & attribution models)
- LvL 3 is the most expensive and quite marginal business (conversion of deep context data to action what to do, strategies & actionable insights)
AI-native hedge funds are coming with scaling LvL 2
AI-native hedge funds are coming, since here is a huge productivity gap in decision-making:
- AI agents can process massive amounts of information and generate LvL 3 outputs
- They can do it well only when they have sufficient, correct inputs (deep context + complete data)
- If context is missing or metrics are incomplete, output quality degrades sharply. Results become inconsistent, and often misleading.
Based on our review of multiple AI-generated dashboards and reports, AI-native capital management is highly sensitive to input quality.
Without Deep Context Data, outcomes deteriorate materially while the required context layer remains largely unsolved.
Supplementary: The Landscape of Web3 Data Production
Who produces data & insights in web3?
Note, that here we provide list as an example and don't pretend to cover all players:
- LvL 0: Indexers (The Graph, Subquery), Dune Analytics
- LvL 1: Defillama, Artemis, Token Terminal, Nansen, Zerion, Messari, Delphi Digital, Blockworks, Dune (custom dashboards), AI-native (FlipsideCrypto, Allium)
- LvL 2: Wallets & Portfolio trackers such as Zerion/Debank (deep context on users' layer), all LvL 1 mentioned do some LvL 2 metrics, dashboard builders on Dune, Valueverse (LvL 2 & Deep Context focused)
- LvL 3: Liquid funds, asset managers, investment advisers, Research Firms (Messari, Delphi, Blockworks, among others) producing custom reports & newsletters, X KOLs, Risk Managers.
Disclaimer: This article and the accompanying analysis are provided by Valueverse for research and educational purposes only. All conclusions discussed herein are experimental in nature and may rely on incomplete, estimated, delayed, or incorrect data, as well as subjective assumptions and methodologies.
Nothing in this publication constitutes investment advice, financial advice, legal advice, or a recommendation to buy, sell, or hold any asset. Readers are solely responsible for their own research, risk assessment, and investment decisions.